COPY
COPY is a special PostgreSQL command that ingests a file directly into a database table. This allows to ingest data faster than by using individual INSERT queries.
PgDog supports parsing this command, sharding the file automatically, and splitting the data between shards, transparently to the application.
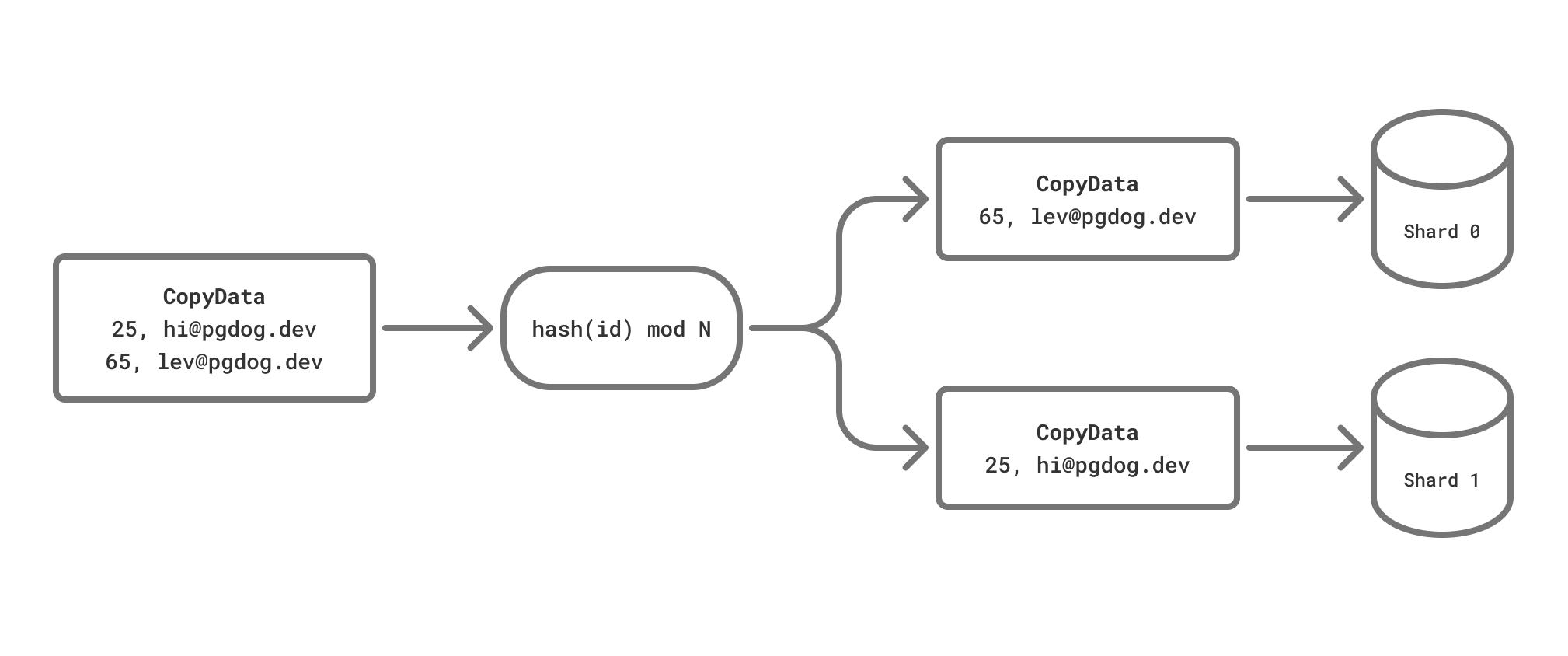
How it works
Data sent via COPY is formatted using one of 3 possible formats:
- CSV (comma-separated values)
- Text (PostgreSQL version of CSV, with
\tas the delimiter) - Binary (not frequently used)
PgDog supports both CSV and text formats out of the box.
Expected syntax
COPY commands sent through PgDog should specify table columns explicitly. This allows PgDog to parse the data stream correctly, knowing which column is the sharding key.
Take the following example:
id,email
1,[email protected]
2,[email protected]
3,[email protected]
To ingest this data into the table, the following query should be used:
This query specifies the column order, the file format, and that the file contains a header which should be ignored. If you're using psql, replace the COPY with the special \copy command.
Note
While it's technically feasible to use the CSV header to determine the column order, it's possible to supply files without headers, and that would require PgDog to fetch the schema definition from the database, making this a more complex, multi-step process.
Performance
Theoretically, by adding N nodes to a sharded cluster, the performance of COPY increases N times. Data sent through COPY is ingested into shards in parallel. This makes the performance of COPY as fast as data nodes can write data and the network can send/receive messages. The cost of parsing and sharding CSV data in PgDog is negligibly small.