COPY command
COPY is a special PostgreSQL command that ingests a file directly into a specified database table. This allows for writing data faster than by using individual INSERT queries.
PgDog supports parsing the COPY command, splitting the input data stream automatically, and sending the rows to each shard in parallel.
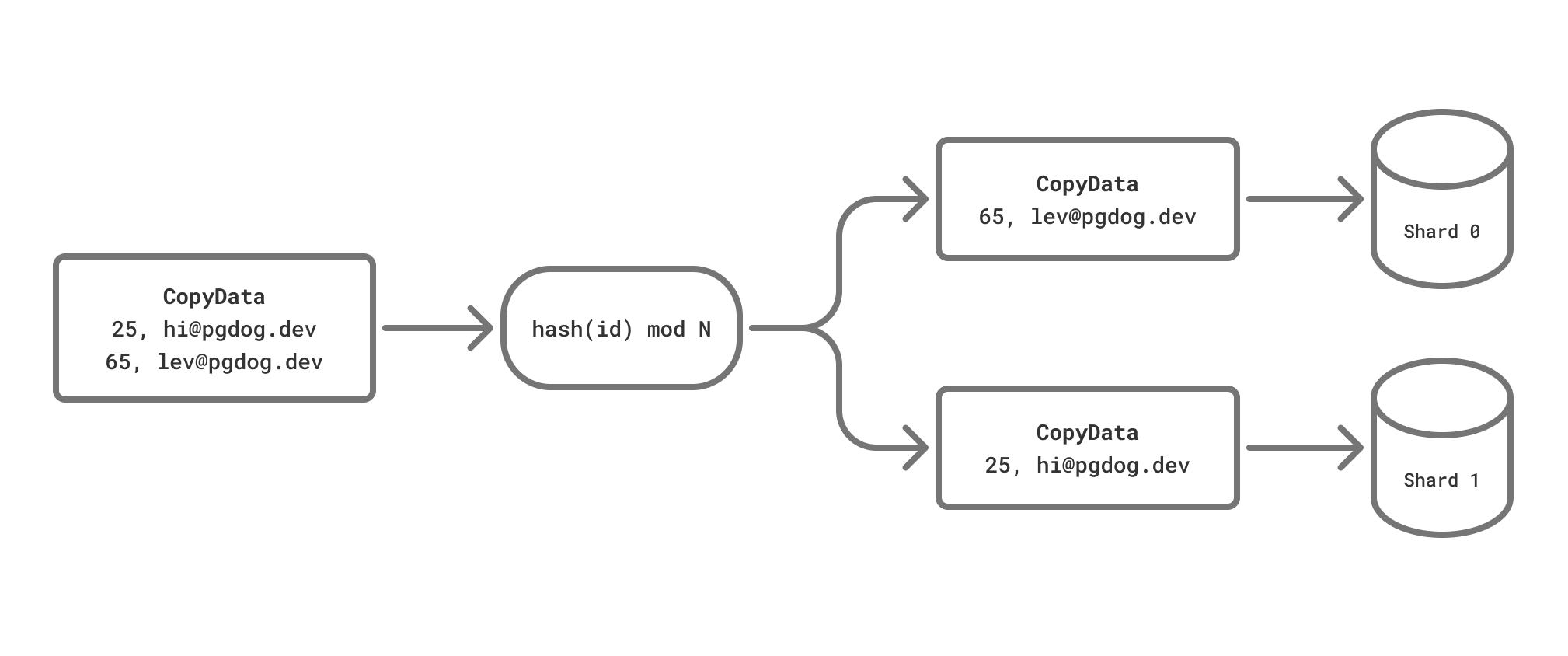
How it works
PgDog supports sharding data sent via COPY, using any one of the following formats:
| Format | Description | Example |
|---|---|---|
| CSV | Comma-separated values, an industry standard for sending data between systems. | hello,world,1,2,3 |
| Text | PostgreSQL version of CSV, with <tab> (\t) as the delimiter. |
hello\tworld\t1\t2\t3 |
| Binary | PostgreSQL-specific format that encodes data using the format used to store it on disk. |
Each row is extracted from the data stream, inspected for the sharding key, and sent to a data node. The sharding key should be specified in the configuration and provided in the command statement, for example:
The columns should be specified in the statement, in the same order as they appear in the input data. If the data has headers (like some CSV files would, for example), they are sent to all shards. The query router doesn't use them to identify rows.
Performance
By using N nodes in a sharded database cluster, the performance of COPY increases by a factor of N. Data sent through COPY is ingested into the data nodes in parallel. This makes the performance of COPY as fast as the shards can write data to disk, and the network can send & receive messages.
The cost of parsing and sharding the CSV stream in PgDog is negligibly small.