Replication and failover¶
PgDog has built-in functionality for monitoring the state of Postgres replica databases. If configured, it can also automatically detect when a replica is promoted and redirect write queries to the new primary, and ban replicas from serving traffic if they have fallen far behind in the replication stream.
Replication¶
When enabled, PgDog will periodically query all databases configured in pgdog.toml to fetch the following information:
- Log Sequence Number (LSN)
- Value returned by
pg_is_in_recovery() - Timestamp of the last transaction
This information can be viewed in real-time by querying the admin database with the SHOW REPLICATION command.
Replication lag¶
In addition to fetching raw metrics, PgDog can calculate the replication lag (also known as "replication delay") between the primary and each replica. The lag is calculated in milliseconds and uses the following formula:
| Step | Description |
|---|---|
| Primary LSN | Get the LSN from the primary using pg_current_wal_lsn(). |
| Replica LSN | Get the LSN from each replica using pg_last_wal_replay_lsn() or pg_last_wal_receive_lsn(). |
| LSN check | If the two LSNs are identical, replication lag is 0. |
| Calculate lag | If the two LSNs are different, replication lag is now() - pg_last_xact_replay_timestamp(). |
This formula assumes that when the replica's LSN is behind the primary, the primary is still receiving write requests. While this is not always the case, it will show replication lag growing over time if the replication stream is falling behind or is broken.
Formula accuracy
It is possible to calculate the exact replication delay in bytes by subtracting a replica LSN from the primary LSN. While this provides an exact measurement, that metric isn't very useful: it's hard to translate bytes into a measurement of how stale the data on the replica truly is.
Approximating the lag in milliseconds is more informative and will be reasonably accurate the majority of the time.
Configuration¶
By default, PgDog will not query databases for their replication status. To enable this feature, configure it in pgdog.toml:
[general]
# Start running the LSN check immediately.
lsn_check_delay = 0
# Run LSN check every second.
lsn_check_interval = 1_000
| Setting | Description |
|---|---|
lsn_check_delay |
For how long to delay fetching replication status on PgDog launch. By default, this is set to infinity, so the feature is disabled. |
lsn_check_interval |
How frequently to re-fetch the replication status. The query used is fast, so you can configure it to run frequently. |
Decreasing the value of lsn_check_interval will produce more accurate statistics, at the cost of running additional queries through the same connection pool used by normal client connections.
It's common for PgDog deployments to be serving upwards of 30,000-50,000 queries per second per pooler process, so you can run the LSN check query quite frequently without noticeable impact on system latency.
Replica lag ban¶
Experimental feature
This feature is new and experimental. Please report any issues you encounter.
If a replica has fallen far behind the primary, it may start serving stale data to the application. This can cause hard to debug issues, so it's often best to remove this replica from the load balancer until it's able to catch up.
PgDog supports this with configurable banning thresholds:
| Setting | Description |
|---|---|
ban_replica_lag |
How far behind in transaction time (ms) can the replica fall before it gets removed from the load balancer. |
ban_replica_lag_bytes |
Same as above, except the lag is measured in bytes. |
The load balancer will use the lowest threshold to make its determination. By default, both settings are set to the maximum integer value, effectively disabling this feature.
Unlike health check-triggered bans, replica lag ban is not cleared after hitting the ban_timeout threshold and will remain in place until the replica lag falls below the configured amount(s). Incidentally, by removing traffic from the replica database, it has a better chance of catching up to the primary, since most causes of replication lag in PostgreSQL are related to query load.
Failover¶
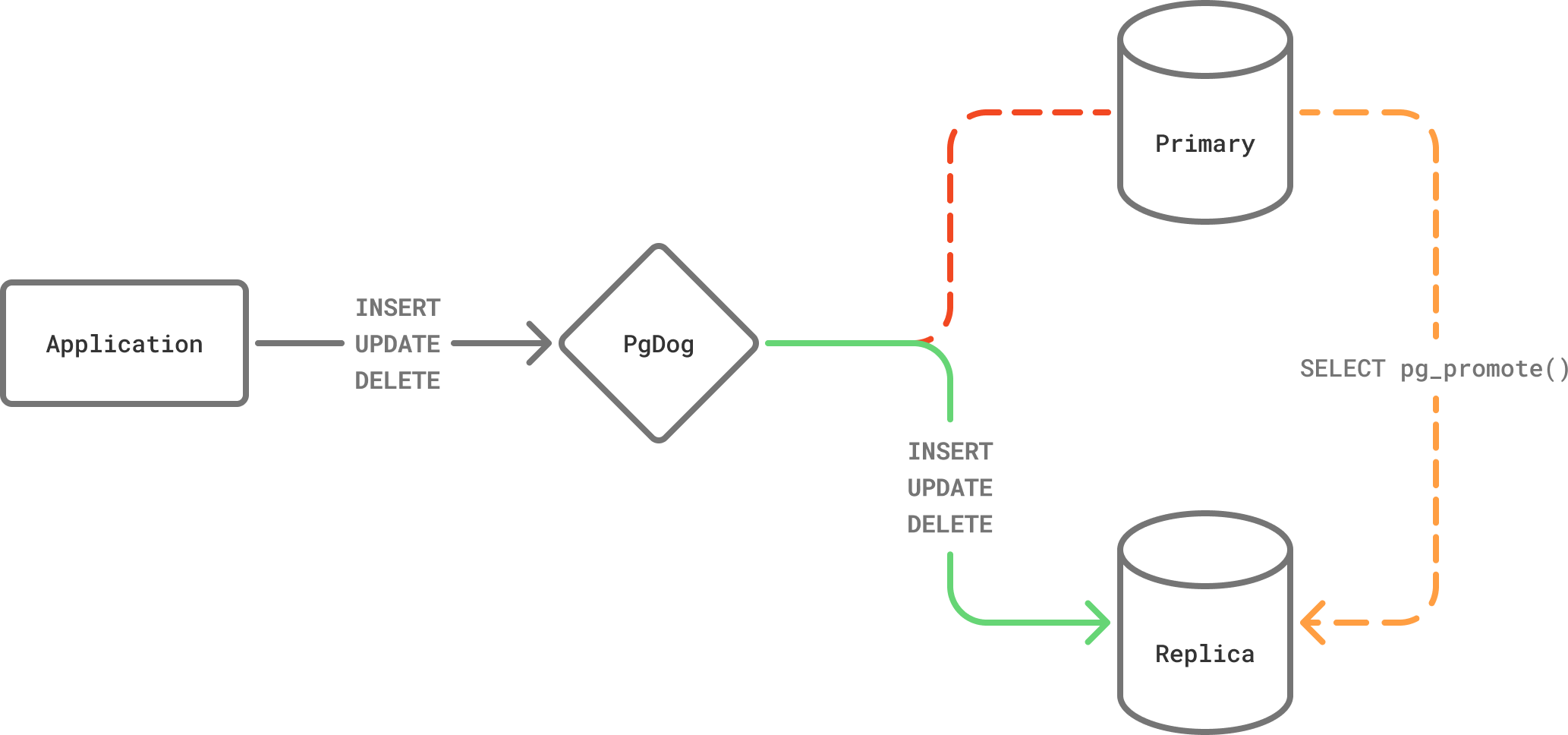
If the pg_is_in_recovery() function returns true, the database is configured as a standby. It can only serve read queries (e.g. SELECT) and is expected to be reasonably up-to-date with the primary database.
Replica databases can be promoted to serve write queries. If that happens, pg_is_in_recovery() will start returning false. You can read more about this in the PostgreSQL documentation.
Failover trigger
PgDog does not detect primary failure and will not call pg_promote(). It is expected that the databases are managed externally by another tool, like Patroni or AWS RDS, which handle replica promotion.
If the pg_is_in_recovery() function returns false, PgDog will assume that the database is the primary and will start sending it write query traffic. The old primary is demoted to the replica role.
Configuration¶
Failover is disabled by default. To enable it, change all configured databases in pgdog.toml to use the "auto" role, for example:
[[databases]]
name = "prod"
host = "10.0.0.1"
role = "auto"
[[databases]]
name = "prod"
host = "10.0.0.2"
role = "auto"
On startup, PgDog will connect to each database, find out if they are in recovery, and automatically reload its configuration with the determined roles.
Split brain¶
If a replica is promoted while the existing primary is alive and serving queries, write queries can be routed to either database, causing data loss. This type of error is called "split brain", indicating that the database cluster no longer has an authoritative source of data it's managing.
PgDog doesn't currently protect against this condition: it solely relies on the value returned by pg_is_in_recovery() to make its routing decisions.
To avoid causing split-brain failures, make sure to use tools like Patroni or managed offerings like AWS RDS, Aurora and others, which correctly orchestrate failovers. If managing replicas manually, make sure to shut down the primary before calling pg_promote() on a replica.
Rewinding
Since PgDog doesn't trigger failovers, it doesn't decide which (most up-to-date) replica should be the failover candidate. It exclusively relies on the value of pg_is_in_recovery() to update its routing tables.
Logical replication¶
Replica databases that use logical replication to synchronize data are, underneath, regular primaries. PgDog is currently unable to detect which database in a logically replicated cluster is the primary and which are replicas.