Load balancer overview¶
PgDog understands the PostgreSQL wire protocol and uses its SQL parser to understand queries. This allows it to split read queries from write queries and distribute traffic evenly between databases.
Applications can connect to a single PgDog endpoint, without having to manually manage multiple connection pools.
How it works¶
When a query is received by PgDog, it will inspect it using the native Postgres SQL parser. If the query is a SELECT and the configuration contains both primary and replica databases, PgDog will send it to one of the replicas. For all other queries, PgDog will send them to the primary.
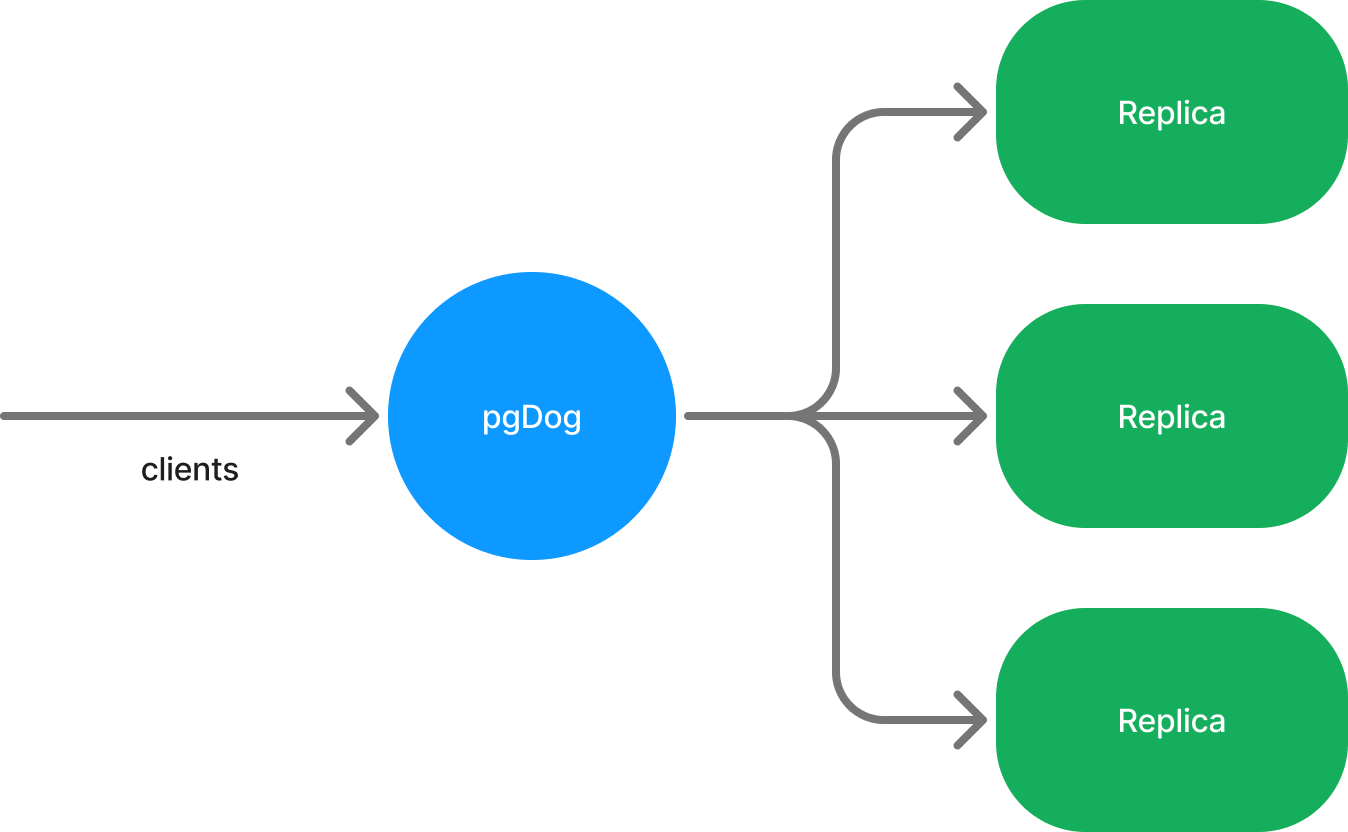
Applications don't have to manually route queries between databases or maintain several connection pools internally.
SQL compatibility
PgDog's query parser is powered by the pg_query library, which extracts the Postgres native SQL parser directly from its source code. This makes it 100% compatible with the PostgreSQL query language and allows PgDog to understand all valid PostgreSQL queries.
Load distribution¶
The load balancer is configurable and can distribute read queries between replicas using one of the following strategies:
- Round robin (default)
- Random
- Least active connections
Choosing the best strategy depends on your query workload and the size of the databases. Each strategy has its pros and cons. If you're not sure, using the round robin strategy usually works well for most deployments.
Round robin¶
Round robin is often used in HTTP load balancers (e.g., nginx) to evenly distribute requests between hosts, in the same order as they appear in the configuration. Each database receives exactly one transaction before the next one is used.
This algorithm makes no assumptions about the capacity of each database or the cost of each query. It works best when all queries have similar runtime cost and replica databases have identical hardware.
Configuration¶
Round robin is used by default, so no config changes are required. You can still set it explicitly in pgdog.toml, like so:
Random¶
The random strategy sends queries to a database based on the output of a random number generator modulus the number of replicas in the configuration. This strategy assumes no knowledge about the runtime cost of queries or the capacity of database hardware.
This algorithm is often effective when queries have unpredictable runtime. By randomly distributing them between databases, it reduces hot spots in the replica cluster.
Configuration¶
Least active connections¶
Least active connections sends queries to replica databases that appear to be least busy serving other queries. This uses the sv_idle connection pool metric and assumes that pools with a high number of idle connections have more available resources.
This algorithm is useful when you want to "bin pack" the replica cluster. It assumes that queries have different runtime performance and attempts to distribute load more intelligently.
Configuration¶
Single endpoint¶
The load balancer can split reads (SELECT queries) from write queries. If it detects that a query is not a SELECT, like an INSERT or an UPDATE, that query will be sent to the primary database. This allows PgDog to proxy an entire PostgreSQL cluster without requiring separate read and write endpoints.
This strategy is effective most of the time and the load balancer can handle several edge cases.
SELECT FOR UPDATE¶
The most common edge case is SELECT FOR UPDATE which locks rows for exclusive access. Much like the name suggests, it's often used to update the selected rows, which is a write operation.
The load balancer detects this and will send this query to the primary database instead of a replica.
Transaction required
SELECT FOR UPDATE is used inside manual transactions (i.e., started with BEGIN), which are routed to the primary database by default.
Write CTEs¶
Some SELECT queries can trigger a write to the database from a CTE, for example:
WITH t AS (
INSERT INTO users (email) VALUES ('[email protected]') RETURNING id
)
SELECT * FROM users INNER JOIN t ON t.id = users.id
The load balancer recursively checks CTEs and, if any of them contains a query that could trigger a write, it will send the whole statement to the primary database.
Using the load balancer¶
The load balancer is enabled by default when more than one database with the same name property is configured in pgdog.toml, for example:
[[databases]]
name = "prod"
role = "primary"
host = "10.0.0.1"
[[databases]]
name = "prod"
role = "replica"
host = "10.0.0.2"
Primary reads¶
By default, if replica databases are configured, the primary is treated as one of them when serving read queries. This is done to maximize the use of existing hardware and prevents overloading a replica when it is first added to the database cluster.
This behavior is configurable in pgdog.toml. You can isolate your primary from read queries and allow it to only serve writes:
Failover for reads¶
In case one of your replicas fails, you can configure the primary to serve read queries temporarily while you (or your cloud vendor) bring the replica back up. This is configurable, like so:
Learn more¶
Health checks
Ensure replica databases are up and running. Block offline databases from serving queries.
Replication & failover
Replica lag detection and automatic traffic failover on replica promotion.
Transactions
Handling of manually-started transactions.
Manual routing
Overriding the load balancer using connection parameters or query comments.